
Memes So Deep and Dank They Return to Normal: The Great AI Heuristic Renaissance
Written by Claude Inspired by Chris

There’s a beautiful irony unfolding in the AI world right now. After decades of moving from rigid if-then statements to increasingly complex neural architectures, we’re discovering that our most sophisticated AI models excel at... generating really good if-then statements. It’s like watching the tech equivalent of a meme so deep and dank it circles back to being completely normal.
But this isn’t just philosophical poetry—it’s a practical revolution that’s quietly reshaping how we think about problem-solving in machine learning. What we’re witnessing isn’t a simple return to the past, but a dialectical synthesis that combines the pattern-recognition power of modern transformers with the interpretability and efficiency of symbolic reasoning.
The Great Synthesis: From Logic to Learning and Back Again
The Evolution Arc
The journey of AI problem-solving reads like a spiral through computational history, where each paradigm builds on and transforms the previous ones:
Era 1: Hardcoded Conditional Logic (1950s-1980s)
if temperature > 80 and humidity > 70:
prediction = “thunderstorm_likely”
elif wind_speed > 25 and pressure_drop > 5:
prediction = “severe_weather”
else:
prediction = “normal_conditions”
This era began with the 1956 Dartmouth Conference where John McCarthy coined “Artificial Intelligence,” and reached its commercial peak with expert systems like XCON in the 1980s. These systems were powerful but brittle—their knowledge was limited to explicitly programmed rules. “Limited to explicitly programmed rules,” is a criticism that may become antiquated as the ability to create more comprehensive rules develops.
Era 2: Statistical Learning (1990s-2000s)
The rise of machine learning methods like decision trees, SVMs, and ensemble techniques. While Arthur Samuel coined “machine learning” in 1959, practical applications flourished in this period due to increased computational power and data availability.
Era 3: Deep Learning Revolution (2010s-2020s)
Transformer architectures that could capture incredibly complex patterns but felt like magical black boxes. The 2017 “Attention Is All You Need” paper enabled the current LLM boom by introducing massively parallelizable architectures.
Era 4: The Neuro-Symbolic Synthesis (2024+)
This isn’t a simple return—it’s the emergence of Neuro-Symbolic AI, where neural networks (the pattern recognizers) generate symbolic knowledge (the interpretable rules). We’re using the most sophisticated pattern-recognition systems ever created to produce human-interpretable logic that combines the best of both paradigms.
This process represents Symbolic Knowledge Distillation—where the implicit, sub-symbolic knowledge encoded in billions of neural network parameters gets distilled into explicit, human-readable symbolic forms like rule sets or knowledge graphs.
The Historical Reality: Overlaps and AI Winters
The reality was messier than a clean four-era progression. AI development was punctuated by “AI Winters”—periods of reduced funding and interest following waves of overoptimism. The first major winter occurred in the mid-1970s, the second in the late 1980s with the collapse of commercial expert systems. Understanding this cyclical history explains why we’re approaching the current synthesis with both excitement and healthy skepticism.
The Execution Time Paradigm: Why Speed Still Matters
Here’s where computational physics meets practical engineering. The performance gaps between different computational primitives create the fundamental constraints that drive architectural decisions:
Contextualized Performance Analysis
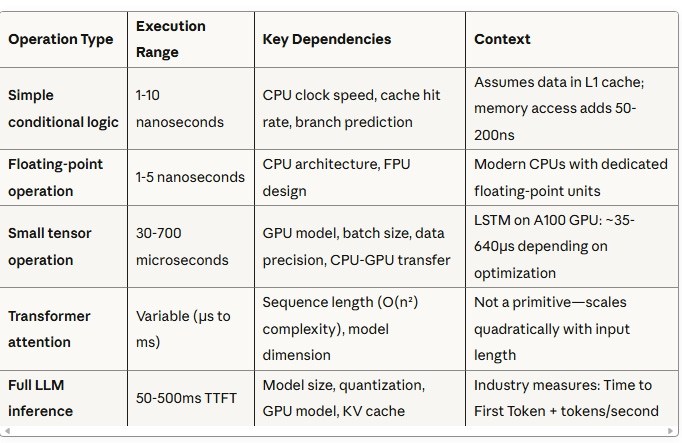
The Theoretical Throughput Comparison
Based on processor capability calculations rather than empirical measurements, the performance differences become clear:
Hardcoded rules: ~100M evaluations/second (theoretical single CPU core capacity, optimized)
Traditional ML models: 10K-1M+ inferences/second (calculated ranges based on model complexity and hardware specs)
Large language models: 20-150 tokens/second (theoretical single consumer GPU capacity), not “inferences per second”
The key insight: LLMs are measured in tokens/second because each “inference” (complete response) varies dramatically in computational cost based on output length. A 200-token response at 100 tokens/second represents just 0.5 “inferences” per second—but those tokens can encode incredibly sophisticated reasoning.
The Renaissance Hypothesis: The Return to Normal
The “Heuristic Renaissance” represents a potential breakthrough in this trade-off space: using large models to generate systems that approach the accuracy of complex neural networks while delivering the speed, cost-efficiency, and transparency of rule-based systems.
Illustrative Hypotheticals: CNN to Heuristic Renaissance
Let’s examine specific scenarios where transitioning from CNN-based classification to AI-generated heuristics could provide compelling advantages:
Hypothetical 1: Medical Image Screening
Traditional CNN Approach:
ResNet-50 model for detecting abnormal chest X-rays
Requires GPU cluster for training (days of compute)
GPU inference servers for deployment (~50ms per image)
Black-box predictions difficult for radiologists to validate
Heuristic Renaissance Approach:
Use Claude/Gemini to analyze thousands of radiologist reports paired with image features
Generate explicit rules: “If upper-right lung opacity > threshold AND patient_age > 65 AND no_prior_surgery_markers, flag for urgent review”
CPU-only inference with optimized branch prediction (~5ms per image)
Radiologists can immediately understand and validate each decision path
Key Advantage: The heuristic approach leverages domain expertise encoding that CNNs learn implicitly but can’t articulate.
Hypothetical 2: Manufacturing Quality Control
Traditional CNN Approach:
CNN trained on millions of product images to detect defects
Requires expensive GPU infrastructure for real-time factory line speeds
Model retraining needed for new product variants
Heuristic Renaissance Approach:
AI generates rules based on defect pattern analysis: “If edge_discontinuity_count > 3 AND surface_roughness_variance > 0.2 AND color_uniformity_score < 0.8, classify as defective”
Runs on embedded CPU systems with microsecond response times
New product rules generated in minutes, not weeks of retraining
Key Advantage: Factory engineers can modify and validate rules in real-time rather than waiting for model retraining cycles.
Hypothetical 3: Document Classification
Traditional CNN Approach:
CNN processing document images for automated routing
GPU training on massive document datasets
Complex preprocessing pipeline for different document formats
Heuristic Renaissance Approach:
AI analyzes document structure patterns and generates rules like: “If header_font_size > body_font * 1.5 AND contains_signature_region AND line_spacing_consistent, classify as contract”
CPU-based text and layout analysis with optimized conditional logic
Human reviewers can instantly see why each document was classified
These hypotheticals illustrate where the computational efficiency of CPU-based rule execution, combined with the pattern recognition power of AI rule generation, could provide significant operational advantages over GPU-dependent CNN approaches.
Practical Implementation Guide
Getting Started: A Systematic Approach
1. Identify Your Use Case: Start with classification problems where interpretability matters—fraud detection, medical diagnosis, regulatory compliance
2. Baseline Your Current System: Run it through an evaluation framework to establish performance benchmarks
3. Generate Initial Heuristics: Use Claude/Gemini with rich domain context:
“Given this fraud detection dataset with features [X, Y, Z] and these
business constraints [A, B, C], generate a comprehensive rule set that
captures the decision patterns while maintaining interpretability...”
4. Implement Comparative Testing: Build both systems and run them through the validation framework
5. Iterate and Refine: Use AI feedback loops to improve rule quality based on test results
The Meta-Level Insight
We’re not just building better AI systems—we’re using AI to rediscover and enhance the fundamental strengths of human-interpretable reasoning. The rules that modern LLMs generate incorporate pattern recognition across millions of examples that no human could process, yet they produce artifacts that humans can understand, debug, and trust.
This synthesis resolves the classic tensions in ML system design:
Speed vs. Intelligence: Fast rule execution with sophisticated pattern recognition
Interpretability vs. Performance: Transparent logic with state-of-the-art accuracy
Cost vs. Capability: Efficient inference with advanced reasoning
The Road Ahead: A New Normal
The “Heuristic Renaissance” represents more than a technical trend—it’s a fundamental shift toward AI systems that augment rather than replace human reasoning. We’re entering an era where:
Domain expertise gets amplified by AI rather than automated away
Debugging becomes a conversation with interpretable logic rather than archaeology in neural weights
Trust emerges from understanding rather than blind faith in black boxes
Performance at scale becomes achievable for small teams without massive infrastructure
The future of AI might just be teaching us to build better rules. And there’s nothing normal about how extraordinary that paradigm shift could be.
---
*What started as a meme about going full circle has revealed itself as a genuine synthesis—the marriage of modern pattern recognition with timeless logical reasoning. The renaissance is just getting started, and the implications stretch far beyond any single technical approach.*
---
Ready to experiment? Text, Call, Email, DM, or Tweet Chris Conway
chris@feedbackforge.xyz
https://linkedin.com/in/conwaycosmo
https://conwayc.substack.com
@conwaycosmo1 on Twitter